ResNet
标签: Paper CNN
Abstract
通过残差网络的引入,极大的增加了CNN的深度,达到了前所未有的152层,在ILSVRC 2015中获得分类、检测第一名
Introduction
更深的网络层次可以帮助模型获得较好性能,但是也带来一些问题:
- 梯度消失/爆炸
原因:前面层上的梯度是来自于后面层上梯度的乘乘积。当存在过多的层次时,就出现了内在本质上的不稳定场景,如梯度消失和梯度爆炸。
Simgmoid容易引发梯度消失,W过大引发梯度爆炸 - degradation的出现
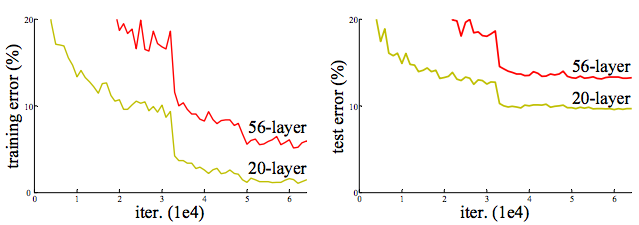
随着网络加深,train erro反而增加,而不是出现overfitting
理论上新加入的层如果做identity映射,网络的性能就不会下降,然而实验表明即使是这样的映射也很难被学习 - 受此启发,本文提出我们可以帮助网络添加一个shortcut,让网络学习除去identification之外的东西,实验表明最优参数接近于identity,所以由于接近0的参数是比较容易学习的,减轻了网络的学习负担

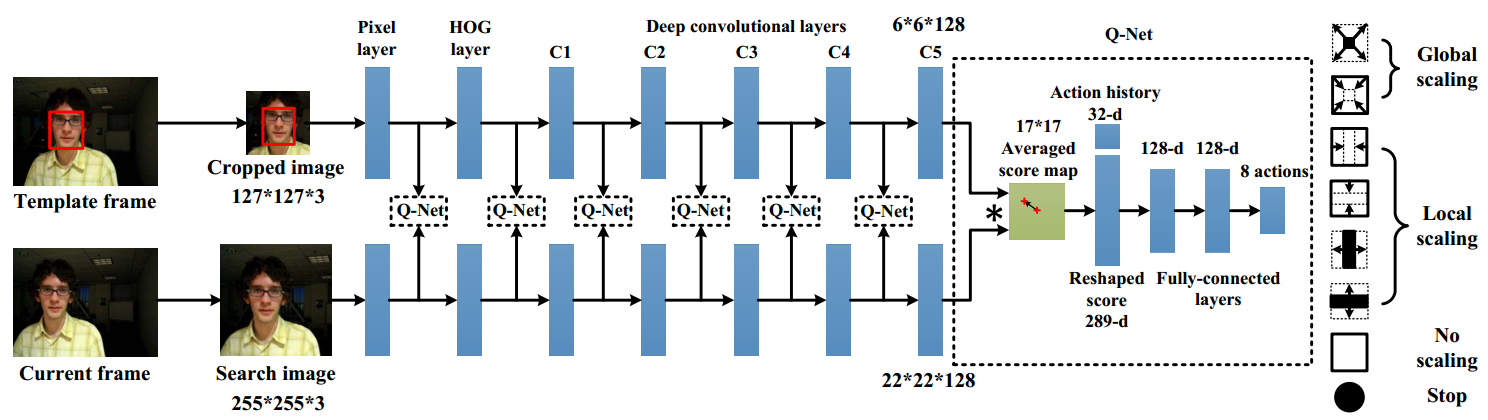
Architecture
公式
只有在维数不匹配时才需要额外的参数Ws(作用在x上),其他情况不会增加参数量
不仅适用于全连接层,也适用于卷积层baseline
inspired by VGG
每次feature map减半时,channel加倍projection
当维数不匹配时,可以选择填充0或引入参数,但维数不变时不引入参数(为了减少运算量和存储开销)bottleneck Architecture
当网络非常深时,使用上图右半部分的残差块,两个11conv filter用于先把channel降低,在通过33后再拔高channel,这样可以降低计算负担,使之与左边残差块计算量相当
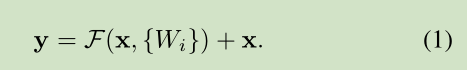

作者还探索了>1000层的网络,但是效果不及100+网络