Abstract
high-resolution 高分辨率
ImageNet Top-1
对一张图片,如果概率最大的是正确答案,则正确
TOp-5 概率前五正确则正确
AlexNet
1.2million images 1000classes
Top-1 erro 37.5%
Top-5 erro 17.0%
60million parameter
5 conv layer + 3 pooling layer
2 ful-con layer
1 softmax layer
no-saturating neurons
使用不挤压输出的激活函数,如relu等,可以减少梯度消失情况的出现
dropout 减少过拟合
Backgroud
- 大规模数据集出现
- CNN有较强模型能力,适于图像处理任务
- GPU对于卷积的优化
Dataset
from ImageNet-2010
256 * 256 缩放+裁剪
预处理:RGB减去分别减去平均值
Achitecture

1. RELU
- 弃用了传统的tanh或是sigmoid,改用$ f(x) = max(0,x) $,大大提高了训练速度
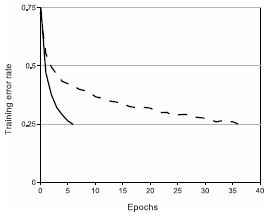
图2:采用ReLUs的四层CNN(实线)对CIFAR-10数据集达到25%训练错误率的速度是采用tanh的CNN(虚线)的六倍。每个网络的学习率(learning rate)都是独立选取以使其训练速度最大化,且都没有经过正则化处理。当然,两种CNN的训练时间上的差距依不同架构会有所不同,但采用ReLUs的CNN总是快过用饱和激活函数的CNN。
2. 多GPU训练
- 在两个GPU并行训练
- 俩个GPU只在某些特定层传递数据
3. 归一化
- 从生物神经中受到启发
- 近邻的较大值可以对自身进行抑制
4. overlapping pooling
3*3 2步长 减少了过拟合
4. 整体架构
- 如上图
input 227 * 227 * 3
conv1 11 * 11 * 3 * 96
active1 55 * 55 * 48 * 2
pool1 27 * 27 * 48 * 2
conv2 5 * 5 * 48 * 128 * 2
active2 27 * 27 * 128 * 2
pool2 13 * 13 * 128 * 2
conv3 3 * 3 * 256 * 192 * 2
active3 13 * 13 * 192 * 2
conv4 3 * 3 * 192 * 192 * 2
active4 13 * 13 * 192 * 2
con5 3 * 3 * 192 * 128 * 2
active5 13 * 13 * 128 * 2
pool5 6 * 6 * 128 * 2
fulc1 6 * 6 * 256 * 4096
active6-7 2048 * 2
sofmax 1000
Reduce Overfitting
- 数据增广
训练数据的载入(以及生成)在CPU上进行,与GPU中的训练并行
- 通过对原图进行变换(256256提取出224224)以及水平翻转,训练集增加2048倍
测试时取五个224*224以及对应水平翻转 - 基于PCA对于每个像素的色彩进行变换,使得物体识别不依赖于色彩
- 随机失活
在前两个全连接层使用随机失活,降低神经元之间的依赖性,失活概率0.5
测试时不进行随机失活,将输出乘以0.5
收敛速度受到了影响
More Detail
- w随机初始化,接近0,b在relu层初始化为1,其他为0,以加快收敛
- 使用随机梯度下降,momentem,weight decay
- 学习率从0.01开始,逐渐降低,每次loss不减小后除10
- 120万图片,90次迭代